

Модели искусственного интеллекта — это не логика, а статистическая манипуляция
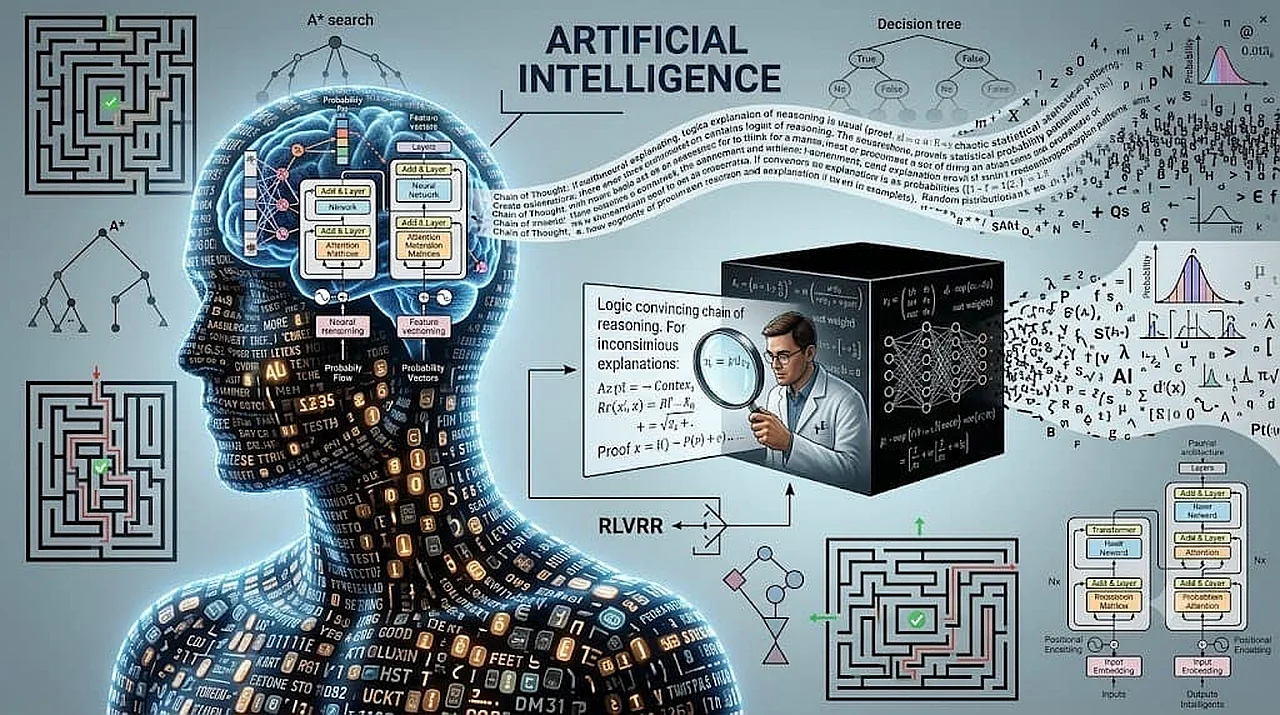
В последние модели OpenAI o1 и DeepSeek R1 поражают мир своей кажущейся человеческой способностью к рассуждению. Об этом сообщил Zamin.uz.
Однако исследователи из Университета Аризоны во главе с Субрао Камбхампати объявили о новом научном исследовании, которое ставит под сомнение эти представления. По словам учёных, длинные цепочки наблюдений в нейросетях на самом деле не являются реальным когнитивным процессом, а представляют собой лишь статистическую манипуляцию.
Согласно мнению исследователей, логические последовательности, генерируемые современными системами искусственного интеллекта, создают у пользователя убедительную иллюзию того, что происходит интеллектуальный процесс. На самом деле же эти модели, основанные на архитектуре Transformer, просто извлекают информацию из предыдущего контекста и делают статистический прогноз следующего слова — и ничего больше.
Сравнение этого процесса с механизмом логического вывода у человека научно некорректно. Особое внимание уделялось моменту «эврики», то есть выражению удивления при понимании сложной задачи.
Учёные утверждают, что это не изменение свойства внутренних вычислений в нейросети, а просто имитация человеческого стиля из обучающих данных. С технической точки зрения, эти системы оптимизированы только для получения окончательного правильного ответа, а промежуточные цепочки не проходят никакой содержательной проверки.
Для проверки своих гипотез исследователи использовали математические задачи, такие как выход из лабиринта и поиск кратчайшего пути. В ходе экспериментов был зафиксирован неожиданный результат.
Модели продолжали находить правильный ответ даже в случаях, когда цепочка логических рассуждений была намеренно ошибочной или запутанной. Это указывает на то, что система не читает свои собственные наблюдения, а использует их лишь как дополнительный статистический шаблон.
Ещё один интересный случай был зафиксирован в простой задаче на лабиринт. Искусственному интеллекту была дана полностью простая, без каких-либо ловушек задача на лабиринт.
Несмотря на это, модели генерировали несколько страниц наблюдений. Это опровергает представление о том, что длина наблюдений отражает вычислительную мощность или сложность.
Длинные тексты появляются просто потому, что в обучающей базе сложные задачи сопровождаются длинными рассуждениями — это чисто статистический побочный эффект. Учёные предупреждают: область искусственного интеллекта рискует погрузиться в театр наблюдений, принимая его за реальность.
Убедительные объяснения, предоставляемые системами, могут ложно усиливать доверие пользователей. Это особенно опасно в таких областях, как медицина, инженерия и юриспруденция, где люди могут принимать важные решения на основе многостраничных текстов, сгенерированных машиной.
Поэтому глубокое понимание внутренних механизмов работы систем искусственного интеллекта и объективная оценка их реальных возможностей имеют важное значение.





